

Part 1 — Looking Back At RPCs — explored how RPCs offered a simple, well-understood, procedure-call interface to communicate with remote systems/apps. The OOP counterparts - CORBA, Microsoft’s DCOM, and Java RMI also derive from RPC. Google’s gRPC and Apache Thrift are the modern reincarnations.

All these frameworks follow the familiar client/server architecture in which a client invokes a procedure that executes on the server. Arguments can be passed from the client to the server and return values can be passed from the server to the client.
Birth Of WebServices
It is hard to say at what point RPCs became Web services as it is an evolutionary tale as there were many technologies between the first RPC and modern WebServices.
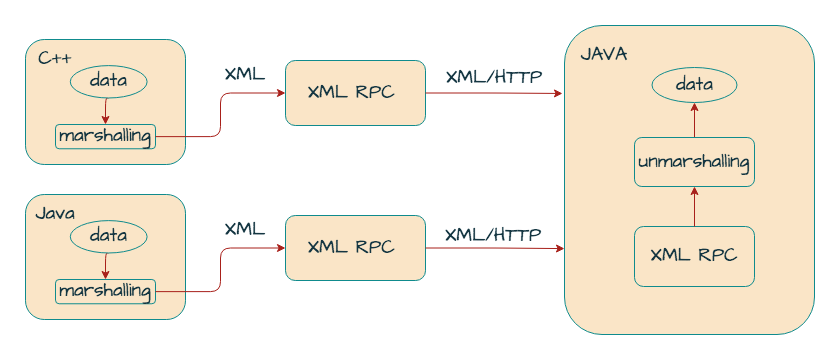
XML-RPC is where we start to de-couple the client from the server. In XML-RPC, payloads are XML (text, as opposed to binary) and commonly use HTTP rather than a proprietary system. To support XML-RPC, a programming language requires only a standard HTTP library and libraries to process XML. SOAP is an XML dialect derived from XML-RPC and is considerably heavier as it tries to standardise many of the stuff between the client and the server. By relying on XML and HTTP, the client and the server need not be coded in the same language or even in the same style of language.
Evolve Independently And Incrementally
Imagine collaborating organisations or even different departments within a large organisation. They all share data and services. Even though there is collaboration, they all largely develop and deploy software on their own terms, at their own pace, and they all use different tech stacks. The challenge lies in enabling this exchange while allowing each entity to evolve independently.
Updating features or data on one side can cause ripple effects, forcing the other side to adapt as well. Clients, which may themselves be services, need to keep working despite of all the changes on the server side. This tight coupling makes independent evolution a complex and potentially disruptive process.
WWW Approach To APIs
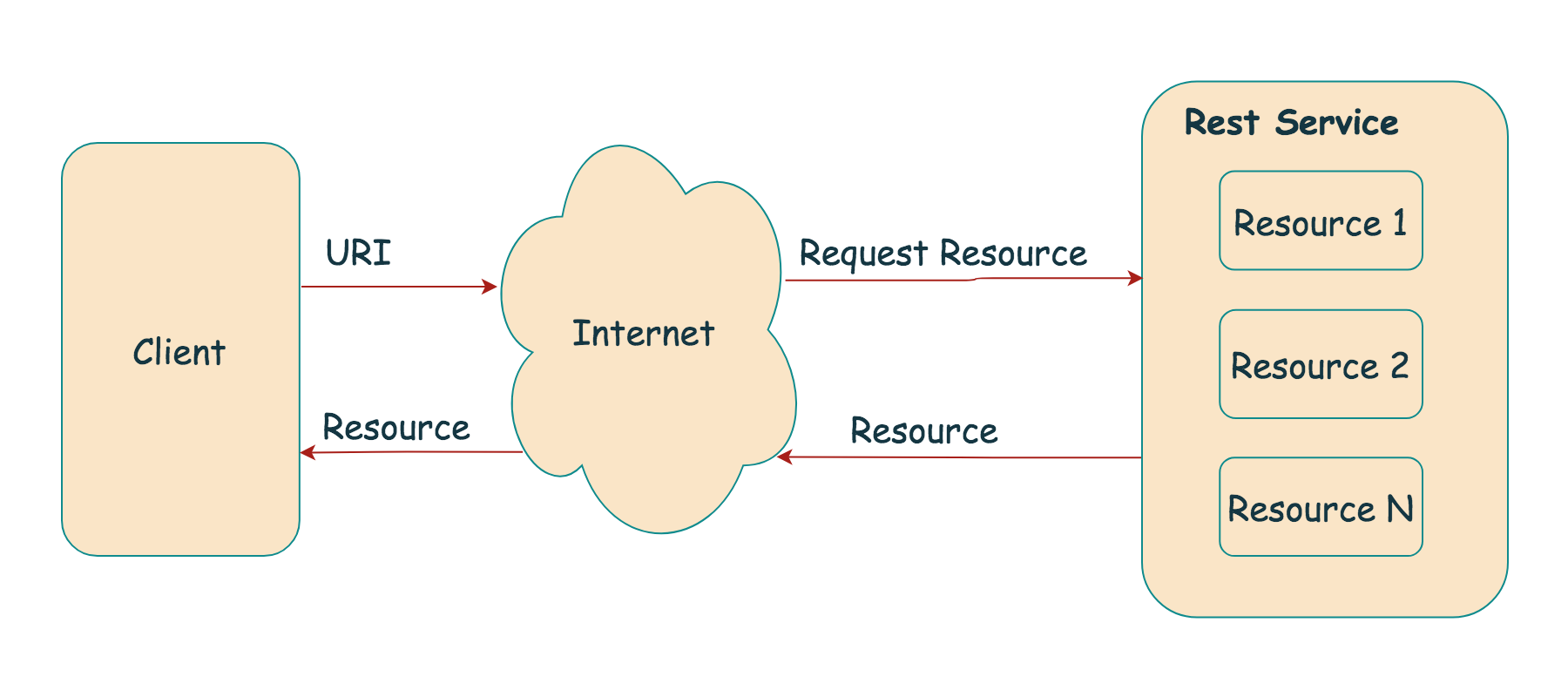
The success of the world-wide-web has led to an alternative model for APIs — Representational State Transfer (ReST). ReST embodies the design principles that underpin HTTP and the world-wide-web itself.
The ReST model is the perfect inverse of the RPC model. In the RPC model, the addressable units are procedures, and the entities of the problem domain are hidden behind the procedures. In the ReST model, the addressable units are the entities themselves and the behaviours of the system are hidden behind the entities as side-effects of creating, updating, or deleting them.
One API To Rule Them All
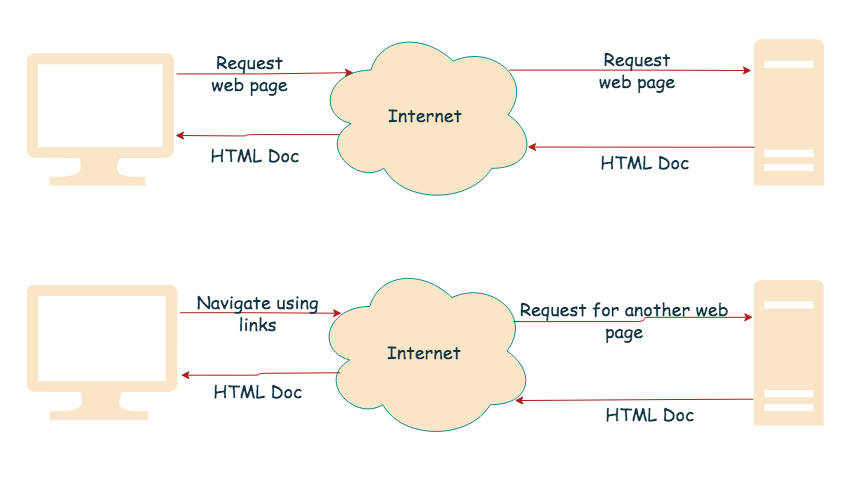
A prominent feature that made WWW a success is the fact that every site on the WWW exposes exactly the same API - the HTTP. The web browsers only need to know a single API to navigate the entire web.
Since HTTP is already so widely known, there’s a lot less to learn about a new API that uses ReST. Compare this to RPC - every new API has to be learnt fresh. Learning an RPC API is very similar to learning a new programming library. The interface of a library is typically made up of many procedures and the signatures of each have to be learned. There’s also little commonality or predictability between procedures in different libraries.
Beyond the Database Analogy
The database analogy, common in introductory materials, treats learning REST APIs like learning a database schema. Both involve well-defined structures accessed through unique identifiers (URLs in REST). However, the analogy breaks down when considering internal details. Clients shouldn't be concerned with resource structure or underlying data models – these are implementation details.
You wouldn’t expose your table names to clients, would you? You shouldn’t force your clients on your resource names, its structure, or its location. They are internal details. Why would the client know what fields are in your tables?
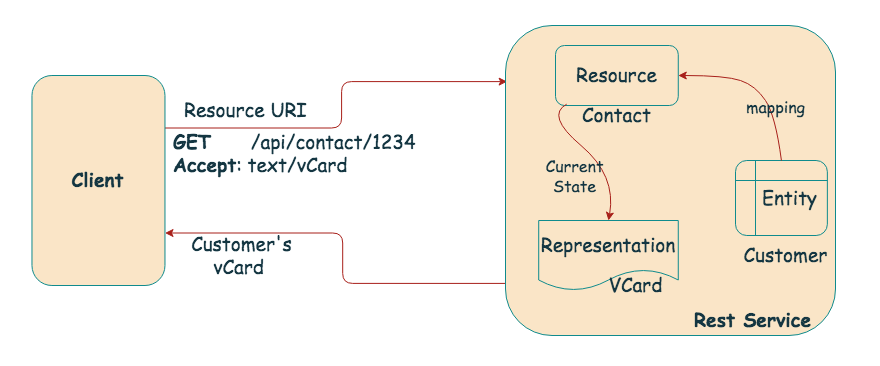
DB Analogy is particularly bad as it gives a false idea that ‘resources’ are the same as the internal data model. They are not the same. Moving beyond the analogy, let's explore the true nature of resources and their relationship to entities within a ReSTful API.
… resources are just consistent mappings from an identifier to some set of views on server-side state. If one view doesn’t suit your needs, then feel free to create a different resource that provides a better view (for any definition of “better”). These views need not have anything to do with how the information is stored on the server, or even what kind of state it ultimately reflects. It just needs to be understandable (and actionable) by the recipient.
— Roy T. Fielding
ReST And Loose Coupling
In a system where clients are de-coupled from the server, clients will in general be fault tolerant and thus robust. In such a system changes done on the server will not affect the client as they adapt to the changes; while a tightly coupled client will fail to process further requests. We should know that for any two systems to be completely de-coupled they must not communicate with each other at all! The goal is to minimise the dependency as much as possible.

In a SOAP API, for example, the tight coupling is defined via the WSDL contract which defines the server endpoint and the operations available to invoke as well as the parameter needed and response types to expect. If the server is adding or (re)moving certain parameters, that client will fail to send further requests and hence needs to be updated before it can continue to work.
In a loosely coupled system, both the client and the server should be able to evolve independently of the other.
ReST achieves this by using two key mechanisms: hypermedia responses and standardised media types. Through hypermedia responses, the server controls the application flow by providing links within the response that guides the client to related resources and available actions. Think of these links as helpful hints from the server, guiding the client on what actions it can take. These links eliminate the need for the client to have pre-programmed knowledge of the entire API structure.
Standardised media types, on the other hand, help with interpreting the data being exchanged. They define the format, structure, and semantics of the data, ensuring both client and server understand the information being sent and received. This allows for independent evolution as changes to the data representation on the server can be communicated through the media type itself, without requiring modifications to the client's understanding of the data format.
If our ReST system (or just the client) fails because the server changed something, then are we really building ReST systems? Does the browser fail because the server changed something?
This hypermedia-driven state transition allows server and client to evolve independently. The server dictates the valid state transitions by providing hypermedia links within responses. These links tell the client what actions are available for a specific resource and how to perform them. While the server controls the state transitions through links, the client still has the freedom to choose which links to follow. This allows for flexibility and exploration within the application boundaries defined by the server.
There is still some dependency - the initial URI and media types. Not everything can be standardised as a media type; domain-specific media types are very much needed. However, there are still ways to work with them through media-type versioning and Code-On-Demand mechanisms.
If the client thinks it knows the URIs beforehand (other than the initial URI) due to a contract, or the URL structure, or something else, you're not in hypermedia, you're into the modern day JSON based soap model.
HATEOAS Is Not Common
Roy Fielding emphasises that adhering to core REST principles, including HATEOAS (Hypermedia As The Engine Of Application State), is crucial for building true RESTful APIs. Simply using HTTP methods and URLs doesn't guarantee a RESTful system.
if the engine of application state (and hence the API) is not being driven by hypertext, then it cannot be RESTful and cannot be a REST API. Period.
— Roy T. Fielding
However, it is important to acknowledge a practical reality: While a powerful concept, HATEOAS is not as widely implemented in real-world RESTful APIs as one might expect. Most developers steer away from this claiming pragmatism. If you are building and exposing APIs to consumers outside your organisation, forget about following HATEOAS; none of your clients will be following HATEOAS and no will use your API.
For an API to be ReSTful, i.e., HATEOAS compliant, the client also needs to be HATEOAS compliant!
While pragmatic considerations often lead to omitting HATEOAS in favour of pre-defined API structures and request-response structures, it's important to be aware of the potential consequences. Skipping HATEOAS lead to tighter coupling between clients and servers, where clients become reliant on specific resource URLs and functionalities. This tight coupling can hinder independent evolution and bears some resemblance to the limitations we saw with RPC-style architectures.
It is much harder to build REST system. It is OK to build non-rest systems if it helps in any way. It is just a matter of knowing what is and is not REST. It is okay to prioritise practicality in certain situations. Understanding REST principles helps you make informed decisions. A well-designed API - even if it doesn’t adhere to all the ReST constraints- can still be efficient and maintainable.