


Looking Back At RPCs
A Programming Abstraction for Distributed Systems

In my previous article - modularity through the ages - I ran through a brief history of major technologies that led us to modern cloud-based distributed systems. I started with RPCs not because it was the first but because it was the most practical and widespread distributed system technology. By that time we already had robust messaging systems; we needed an abstraction that would enable building distributed applications easily.
One such attempt was to extend the operating system's memory management concepts to a network of computers. This approach is called Distributed Shared Memory (DSM). With DSM, processes on different machines could share a large, virtual address space among themselves. People called such systems multicomputers. Most DSM systems work using the virtual memory system of the OS. When a page is accessed on one machine either the page is available in local memory or not. In the best case, the page is already local on the machine, and thus the data is fetched quickly. In the second case, the page is currently on some other machine, and a page fault occurs. The page fault handler sends a message to some other machine to fetch the page, install it in the page table of the requesting process, and continue execution.
This OS abstraction turns a distributed computation into something that looks like a multi-threaded application; the only difference is that these threads run on different machines instead of different processors within the same machine.
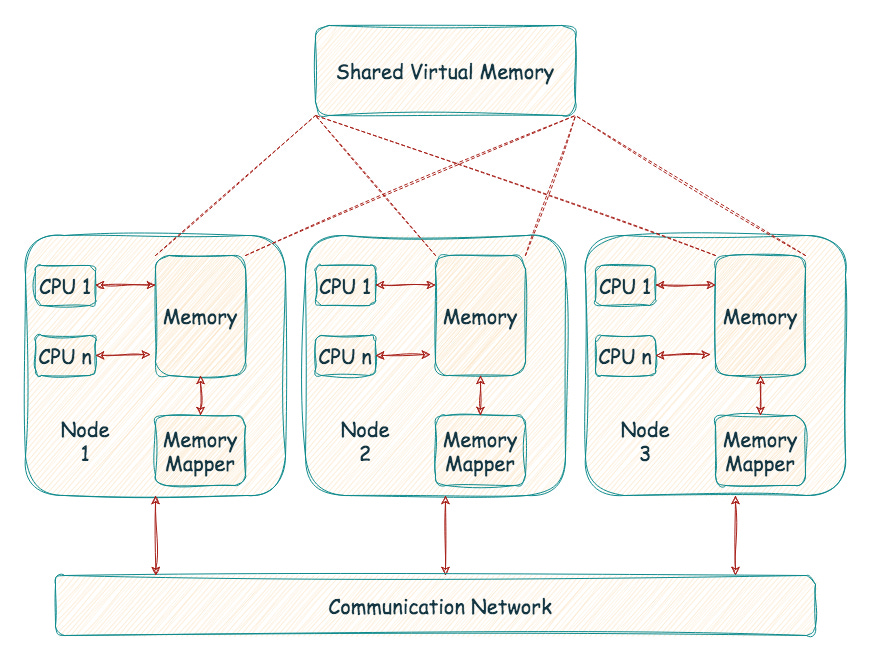
This is convenient for developers. The distributed nature of the application is transparent to them. There is no explicit message passing; there is no visible distinction between code that works in a single machine (address space) or distributed setup.
However, this transparency comes at a cost. When a program tries to access data, it might not be readily available locally. In this case, a page fault occurs, and the data needs to be fetched from another node over the network. This network transfer is significantly slower than accessing local memory. Because developers can't control data location, they can't predict how long a memory access might take. This makes it difficult to optimise code for performance.
To avoid performance penalties, developers might resort to managing data access patterns, ensuring almost no pages are fetched remotely. This defeats the purpose of using a shared memory model in the first place. There are other challenges as well - when a node fails, it affects the entire application. Failures are not localised. What happens to the data in that failed node’s memory?
A Programming Abstraction
As OS abstractions turned out to be a poor choice for building distributed systems, programming language abstractions were attractive. Procedure calls were a well-known and well-understood mechanism for the transfer of control and data within a program running on a single computer. It made sense to extend the same mechanism for the transfer of control and data across a communication network. Thus, the idea of a remote procedure call, or RPC for short.
Remote Procedure Calls (RPCs) have a straightforward mechanism. The machine initiating the call (caller) makes a procedure call over a network to the machine providing the service (callee). The callee machine then executes the procedure locally, gathers the results, and sends them back to the caller.
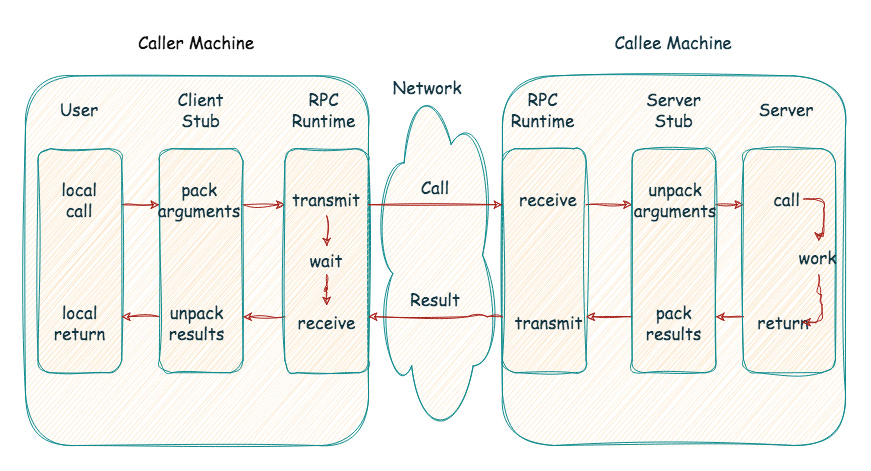
The RPC runtime and stubs carry out all the magic behind RPC. The stubs are auto-generated based on a common interface defined in an IDL (Interface Definition Language). The client stub acts like a local function for your program. When you call it, the stub takes care of converting arguments into a network-friendly format - called marshalling and sending it to the server-side stub. There, the data is unpacked (unmarshalling) and the actual server procedure is called. The result is then marshalled, sent back, unmarshalled by the client stub, and returned to your program as if nothing out of the ordinary happened.
The RPC runtime library tackles many of the complex tasks behind the scenes, ensuring efficient and reliable communication. These tasks include handling data transmission, acknowledgements, retries, packet routing, and encryption.
While the code appears as a simple function call to the client, what happens when multiple clients try to call the same server procedure at the same time? A simple server just waits for requests in a simple loop and handles each request one at a time. However, as you might have guessed, this is very inefficient. if one RPC call is blocking (e.g., on I/O), every other call is simply waiting wasting precious server resources. We usually employ some form of ‘threading’ to overcome this limitation. However, concurrency comes with its costs, mostly in programming complexity. The RPC calls may now need to use locks and other synchronisation primitives to ensure their correct operation.
Naming, Registry, and Discovery
When a client calls a remote procedure, how does the RPC system know which procedure on the remote system is to be called? And in a cluster of machines, which machine hosts that particular procedure? How do I pick a machine when more than one hosts the same procedure?
A name is a string of characters (or bytes) that identifies an entity. Naming is a service using which entities can be identified and accessed only by name, regardless of where they are located. The entity can be just about anything — it can be a user, a machine, a process, or a file. To log in to a remote machine, a user has to provide a login name. On the WWW, the Domain Name Service (DNS) maps domain names to IP addresses. Users cannot send emails to one another unless they can name one another by their email addresses. A naming service keeps track of a name and the attributes of the object that it refers to. Given a name, the service looks up the corresponding attributes(name resolution).
Client-side config - the practice of manually defining the locations (URLs or addresses) of the services that the client needs to interact with - is the default in many RPC systems. However, it is inefficient if you want servers to be added or moved. In such a dynamic environment the RPC runtime on the server side ‘registers’ itself with a registry service providing it its name, the procedures it exports (interface), and the location (address). When a client calls a remote procedure, the discovery service looks up the procedure and returns all the servers (addresses) that have registered as providers of that procedure.
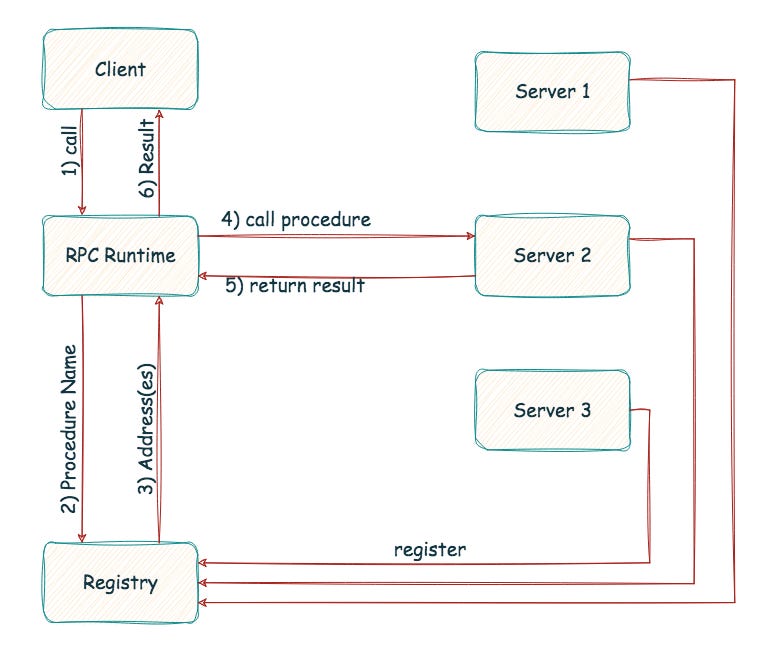
With client-side discovery, the RPC runtime at the client making the request is responsible for identifying the location of the service instance and routing the request to it. It begins by querying the service registry to identify the location of the available instances of the service and then determines which instance to use. The load balancing logic can be a simple round-robin approach or use a weighting system to determine the best instance to query at a given time.
The alternative to client-side discovery decouples the service discovery and load-balancing logic from the client. With the server-side discovery, the client issues RPCs to a proxy. The proxy queries the registry for available instances of the service and distributes the RPC call to one of the available servers that implement the procedure. The proxy keeps track of the load on each server and implements algorithms for distributing load fairly.
Transport
At this point, we can make a remote call and let the RPC system pick a suitable remote procedure to invoke. Is this all? Local calls always return, unless when stuck in an infinite loop in which case it never returns. What about remote procedures? They too respond with success or error/exception most of the time, but there is another scenario where the procedure returned but the client did not receive the response. There can be a network failure, or the client simply timed out — it can’t wait forever, can it?
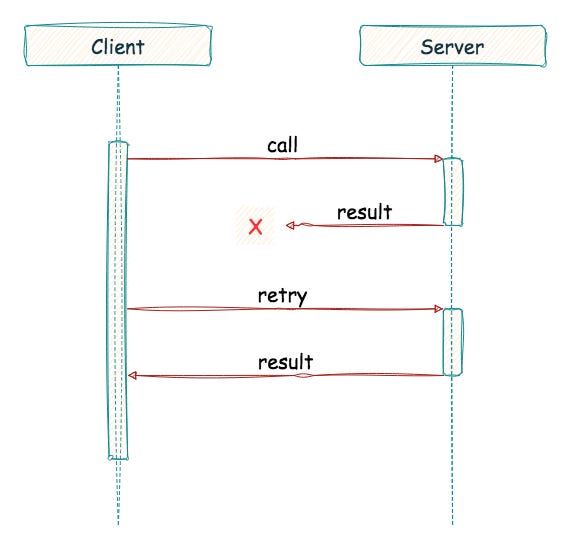
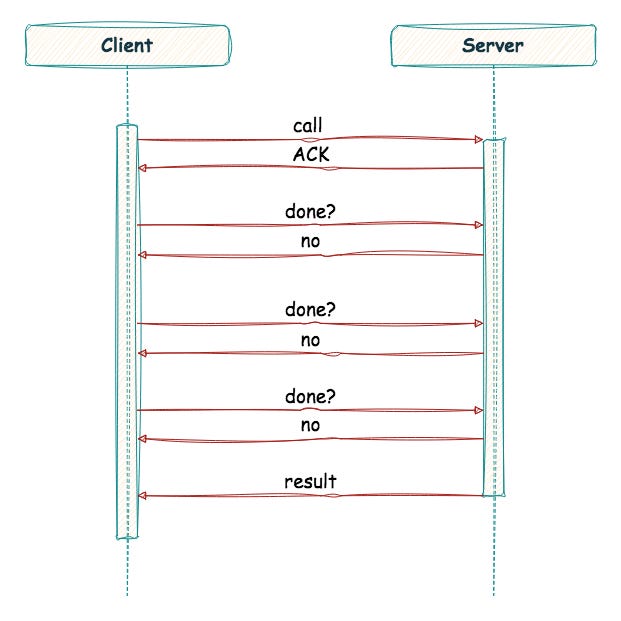
This leads us to another important question: does using a reliable transport protocol like TCP make sense? What happens when a remote call takes a long time to complete? If we add in a time-out mechanism, a long-running remote call might appear as a failure to a client, thus triggering a retry - which we don’t want all the time. One solution is to use an explicit acknowledgement when the reply isn’t immediately generated. This lets the client know the server received the request. Then, the client can periodically ask whether the server is still working on the request. If the server keeps saying “yes”, the client should be happy and continue to wait. TCP already has this ack-retry mechanism built in. We are adding one more layer of the same ack-retry on top of it. Many of the earlier RPC packages are built on top of unreliable communication layers (e.g. UDP) and then bake in the extra logic for dealing with ACKs, retries etc.
Some popular RPC systems used today are gRPC and Apache Thrift. gRPC uses Protocol Buffers for data serialisation and HTTP/2 for transport. This allows gRPC to take advantage of features such as multiplexing and flow control, which can improve performance in high-traffic environments. Apache Thrift has been optimised for low latency and high throughput, making it a good choice for applications that require fast response times.
Knowing the specifics of an RPC system is a must if you want to pick one that is best suited for your use case. But more importantly one must understand what makes RPCs tick. What RPCs offer is a procedural abstraction that mirrors familiar function calls to build distributed systems. However, choosing the right communication paradigm for distributed applications goes beyond just familiarity with abstraction and performance. In part two we will explore how it compares to a contrasting approach: Representational State Transfer (ReST) which offers an Entity abstraction as an alternative approach.