


Driving AI Code: Why Test-Driven Development is Essential in the LLM Era

The Double-Edged Sword of LLM Code Generation
Alright, let's be real for a moment. If you're involved in tech, it's next to impossible to ignore Large Language Models (LLMs) these days. They've evolved from experimental curiosities into powerful, everyday tools that are fundamentally changing how we approach coding. This isn't theoretical; it's just how we do things now, offering a significant "superpower" to developers.

The biggest thing LLMs do for us is AI-powered code generation. Tools like GitHub Copilot (an AI pair programmer for autocompletion and suggestions), Google Gemini Code Assist (Google's AI coding assistant), Amazon Q Developer (which evolved from CodeWhisperer, offering conversational AI for developers), Sourcegraph Cody (known for its deep IDE integration and chat features), and Cursor (an AI-native IDE built around LLMs) are no longer novelties. We're actively using them for quick boilerplate generation, efficient function and module drafting, and providing smart autocompletion right in our IDEs. On top of that, conversational LLMs such as ChatGPT (OpenAI's conversational AI) and Gemini (Google's conversational AI) have become go-to assistants for debugging help, explaining errors, and even generating documentation and comments. All this means one thing: huge speed and efficiency gains. We can get routine tasks done way faster, and prototype at a pace we couldn't imagine before.
The Core Problem: The "Dump" Phenomenon and Eroding Understanding
Okay, so LLMs are super fast. Here’s the catch, one we often don’t notice until it’s too late: they tend to "dump" big, complete code chunks when you give them a broad prompt. Looks productive, right? But it skips something crucial: the human process of incremental design derivation.
When we build something step-by-step, we're not just writing code, we're actually designing it. We're breaking down problems, making conscious architectural choices, and solving small pieces incrementally. This builds our deep understanding of how the solution works inside, its structure, and why it's built that way. When an LLM just dumps code, we miss that crucial journey. We get the "what," but often lose the "why" and "how" of its internal design. That's the anti-pattern we're talking about.
This brings us to the main question for this essay: How do we use LLMs' amazing speed without giving up on that fundamental understanding and design integrity?
How do we use LLMs' amazing speed without giving up on that fundamental understanding and design integrity?
The Implicit Question: New Power, New Responsibilities?
The allure of accelerated development with LLMs is undeniable. One might be tempted to simply "prompt and integrate," riding the wave of newfound productivity.
However, any significant technological power, especially one as transformative as generative AI, inherently introduces a new set of responsibilities and subtle challenges. It's not merely about speed; it's about what that speed might inadvertently compromise if not approached with caution. We must consider the potential trade-offs in areas such as code quality, long-term maintainability, and the overall reliability of the software we are building. The landscape is shifting rapidly, prompting a critical question: how do our existing, proven software engineering disciplines adapt in this new era? Does the convenience of generated code inadvertently create new blind spots or introduce unforeseen complexities down the line? This is not to diminish the potential of LLMs, but rather to acknowledge that harnessing it responsibly requires a critical re-evaluation of our approach.
Any new power, especially one as transformative and inherently complex as generative AI, doesn't arrive without its own set of nuanced challenges.
Test-Driven Development (TDD), through its disciplined, test-first approach, directly counters the "dumping" behaviour of LLMs by forcing incremental design evolution and fostering deep developer understanding, leading to higher quality, more maintainable, and adaptable code that LLMs alone cannot provide.
As you consider this ‘heavy’ claim, you might immediately be asking yourself:
"Why should I, the developer, need to deeply understand the design? Can't I just ask the AI to 'fix' any bugs by giving it a detailed description, and avoid slowing down during development?"
"Instead of building my own understanding, why can't I just provide the entire codebase to the AI and ask it questions to grasp its design, logic, and intricacies?"
"If automated documentation is an LLM 'superpower,' isn't asking the AI to generate documentation a better alternative to building understanding through coding, and won't that save significant time?"
These are valid questions, reflecting common assumptions about LLM integration. But, as we'll see, the answers here point to deeper problems and pitfalls than just how easy it seems right away.
The Technical Deficiencies of Un-Guided, LLM-Dumped Code
Okay, we've seen how LLMs offer a real superpower. But there's a flip side. In this part, we'll explore the technical risks that arise when LLMs generate code without careful guidance.
Opaque Logic: Hallucinations, Subtle Bugs, and the "Why"
We've talked about the "dump" phenomenon – that tendency for LLMs to spit out big, complete code chunks from broad prompts. It looks like progress, right? But this approach often hides a critical flaw: the code can be a black box. You see it, but you don't really get why it was generated that way, or the actual logic the LLM followed. This isn't just theory; it directly hurts our software's quality and reliability.

The trickiest issue here is hallucinations, a known problem with LLMs, as detailed by research by Arjun Krishna et al. (2025). They guess the next most likely word or code token based on patterns, not true understanding or reasoning. Sometimes, this guess gives you code that looks perfectly fine but is logically wrong, doesn't actually work, or even uses APIs that don't exist. They might make up a function call or misuse a library in a way that seems okay but quietly breaks your code.
When an AI "dumps" a solution, these quiet logical flaws are way harder to spot. We're left debugging code where we don't understand its design, which makes it a nightmare to fix.
It's not just a bug; it's a bug in something alien, and trying to find the "why" becomes a long, frustrating headache.
Hidden Security Debts: Vulnerabilities from Un-Derived Design
Beyond logic errors and hallucinations, there's an even bigger problem when you just accept "dumped" code: hidden security debts. This isn't about obvious mistakes; it's about subtle vulnerabilities that sneak into your code because you, the human, didn't actively design it to prevent them. When an LLM generates code, it usually just focuses on making it functional. It doesn't think about security like a human architect would, especially when things get complex.

Security pros have widely shown that LLMs, through well-known attack vectors like "prompt injection," can be tricked into generating insecure patterns, or how their training data accidentally picks up flawed or vulnerable code snippets that get copied, a concern highlighted in research by Kharma et. al. (2025). Spotting these issues in a big, pre-generated code block is incredibly tough. Without that iterative, test-driven process where you intentionally think about security at each small design step, these vulnerabilities become hidden landmines. They create a huge security debt that's expensive and dangerous to fix later. It's not just about making the code work; it's about building secure systems from the ground up, and that needs a human eye on every piece of logic as it's laid down.
The Maintenance Trap: The High Cost of Opaque Code
One of the biggest and most sneaky problems with relying on LLM-dumped code is that it always leads to more and more maintenance work and complexity. For experienced developers, this isn't just "bad code"; it's getting stuck with code where the crucial aspects such as why it is structured that way, how it works, and what it assumes, are mostly missing from human understanding. This lack of design ownership and clarity directly jacks up the cost of changing software.
We have seen codebases, even one just a couple of years old, are called "legacy" and "untouchable" if the developers don’t understand the code.
Developers, everywhere, just hesitate to touch opaque code. The LLM "dump" phenomenon only makes this existing problem worse, speeding up how fast code turns from an asset into a liability.

Future changes, bug fixes, performance boosts, or new features become a nightmare. Instead of extending a clear, well-understood system, you get stuck wrestling with a black box. Every change turns into a risky, time-consuming archaeological dig, trying to figure out the design that was never truly human-designed. This creates brittle code, a big reluctance to refactor, and eventually, a codebase that costs more and more to change and update. The initial "speed gain" from the LLM dump is quickly lost to huge, often unseen, long-term costs. It also kills a team's confidence in being able to update and maintain the software. It's like taking over a complex, undocumented machine – you can press the buttons, but you truly don't know how to fix it when it breaks or make it do something new efficiently.
Sometimes developers call these outcomes – more maintenance work, complex changes, and less clarity – "technical debt." But most see it differently. True technical debt often comes from a calculated choice to deliver fast, knowing you'll fix things later. The problems with LLM-dumped code, though, are usually an unintended side effect of not having a clear design process. It makes the code a black box where the "why" was never consciously built in. This burden is more like a surprise liability than a planned debt.
Non-Determinism vs. Deterministic Control
Software development is, at its core, all about determinism. When we write code, we expect the same input to always give us the same output, and our tests to reliably pass or fail every time. This predictability is key to building solid systems. But here's the thing: Large Language Models inherently mess with this.
LLMs are probabilistic. Their outputs are based on probabilities, meaning the same prompt can produce slightly different versions of code, even with identical input, a characteristic of their probabilistic nature (Neptune.ai, 2024). This non-deterministic behaviour creates a quiet but big problem in development. When using LLM-dumped code, you might get a working solution one minute, then a subtly different, maybe broken, version next. This makes traditional testing trickier. Simply re-running tests against a new LLM generation doesn't guarantee the same logic or assumptions are maintained. Without a human-driven process to clearly define how things should work through small, specific tests, the LLM's unpredictable nature can kill confidence in the code. It makes it harder to understand, debug, and ultimately trust. It pushes the job of making things predictable from the coder to the person checking the code, often after it's already built.
Overreliance and the Erosion of Developer Understanding
LLMs' amazing efficiency comes with a silent, but big, risk: overreliance, as explored in academic work by Jošt (2024). When a powerful AI can quickly spit out huge code sections, it's super tempting for developers to just accept the output, maybe glance at it, and move on. This "prompt and integrate" mindset, while it seems fast, really eats away at your deep understanding of the code you're building.
This isn't just about being lazy; it's a system-wide problem. If you're not actively involved in tiny design decisions, breaking down problems, and understanding the "why" behind each piece of logic, you're basically giving up control over how the code works.
If you're not actively involved in tiny design decisions... you're basically giving up control over how the code works.
When the LLM "dumps" a solution, you become a checker of outside code instead of a designer or engineer. Over time, this lessens your understanding of the system's complexities, how its parts connect, and the small trade-offs made during building. This loss of understanding messes with everything: effective debugging, confident refactoring, and smart future planning. Without that internal mental map built by actively participating in design, you just manage code you don't truly get, leaving you unprepared for tough, unexpected problems LLMs can't handle yet.

This passive acceptance, caused by LLMs "dumping" full solutions, actually stops you from getting that deep understanding. It creates a quiet but big contradiction: LLMs promise efficiency, but just going along with their output can actually make you less effective at using them well. The skill to write precise, guiding prompts – to break complex problems into small, AI-friendly pieces – becomes key to being a good developer.
If you don't really understand the code's evolving design, you won't even know what to ask the AI, let alone how to check its big, dumped answers.
So, the fake speed of the LLM "dump" pattern actively works against building the very skills you need for real, long-term AI-assisted productivity.
Contextual Limitations
Beyond the immediate quality and how easy it is to understand LLM-generated code, one other big worry that pushes home why we need human oversight and good design practices is LLMs' inherent contextual limitations, a technical aspect well-explained by Google Cloud..

Even though LLMs are super powerful, they only work within a limited context window due to the computational demands of their architecture (like the attention mechanism). They're great at generating code based on your immediate prompt and a small bit of surrounding code (like a few hundred lines in your IDE). But real-world enterprise codebases – thousands or millions of lines, complex architectures, deep domain-specific logic – are way bigger than any LLM's current context window can handle. This means LLMs struggle to make code that truly fits into a big, existing system, or to correctly understand and use complex internal APIs without a human constantly guiding them. The code they "dump" for a big task will often be generic, missing project-specific design choices or existing parts, so you'll have to do a lot of human refactoring and integration anyway.
Intellectual Property (IP) and Copyright Concerns
Before we dive into this, a quick meta-note: this section, which touches on complex legal territory, is, un-ironically, crafted by an AI. Food for thought, right?
The domain of Intellectual Property (IP) and copyright concerning LLM-generated content presents multifaceted challenges within the prevailing legal and ethical frameworks. LLMs are trained on extensive datasets that may frequently incorporate copyrighted materials. Consequently, outputs generated by these models can exhibit substantial similarity to, or direct replication of, pre-existing copyrighted works. This inherently introduces potential legal liabilities for organisational entities and contributes to ambiguities regarding ownership rights. While a comprehensive elucidation of this evolving legal landscape is beyond the scope of this exposition, its significant implications necessitate acute awareness. This concern underscores the critical imperative for human oversight and rigorous review processes in the development pipeline. For in-depth analysis and authoritative guidance on this subject, consultation with legal professionals and specialised organisations within the fields of Artificial Intelligence and Intellectual Property is strongly recommended.
TDD: The Methodology for Human-Driven Design Evolution and Deep Understanding
We've explored the very real pitfalls of relying on LLM-dumped code: the opaque logic, hidden security issues, the maintenance trap, and that dangerous erosion of true developer understanding. So, how do we counter this? How do we leverage AI's speed without sacrificing the fundamental principles of robust software engineering? For us, the answer lies squarely in Test-Driven Development (TDD). The efficacy of this integration is not merely theoretical; its ability to improve LLM-generated code quality has been empirically demonstrated by recent research by Mathews & Nagappan(2024).
TDD: Test-First, Design-Driving, Understanding-Building
While TDD is often mistakenly reduced to "just testing," its original and most profound purpose has always been to drive design. In the LLM era, this design-driving aspect becomes not just important, but absolutely essential. It's the methodology for actively fostering incremental design evolution and building profound developer understanding, a perspective increasingly validated by contemporary research on LLM code generation (Fakhoury et al., 2024).
"TDD helps you to pay attention to the right issues at the right time so you can make your designs cleaner, you can refine your designs as you learn."
— Kent Beck, Test-Driven Development: By Example
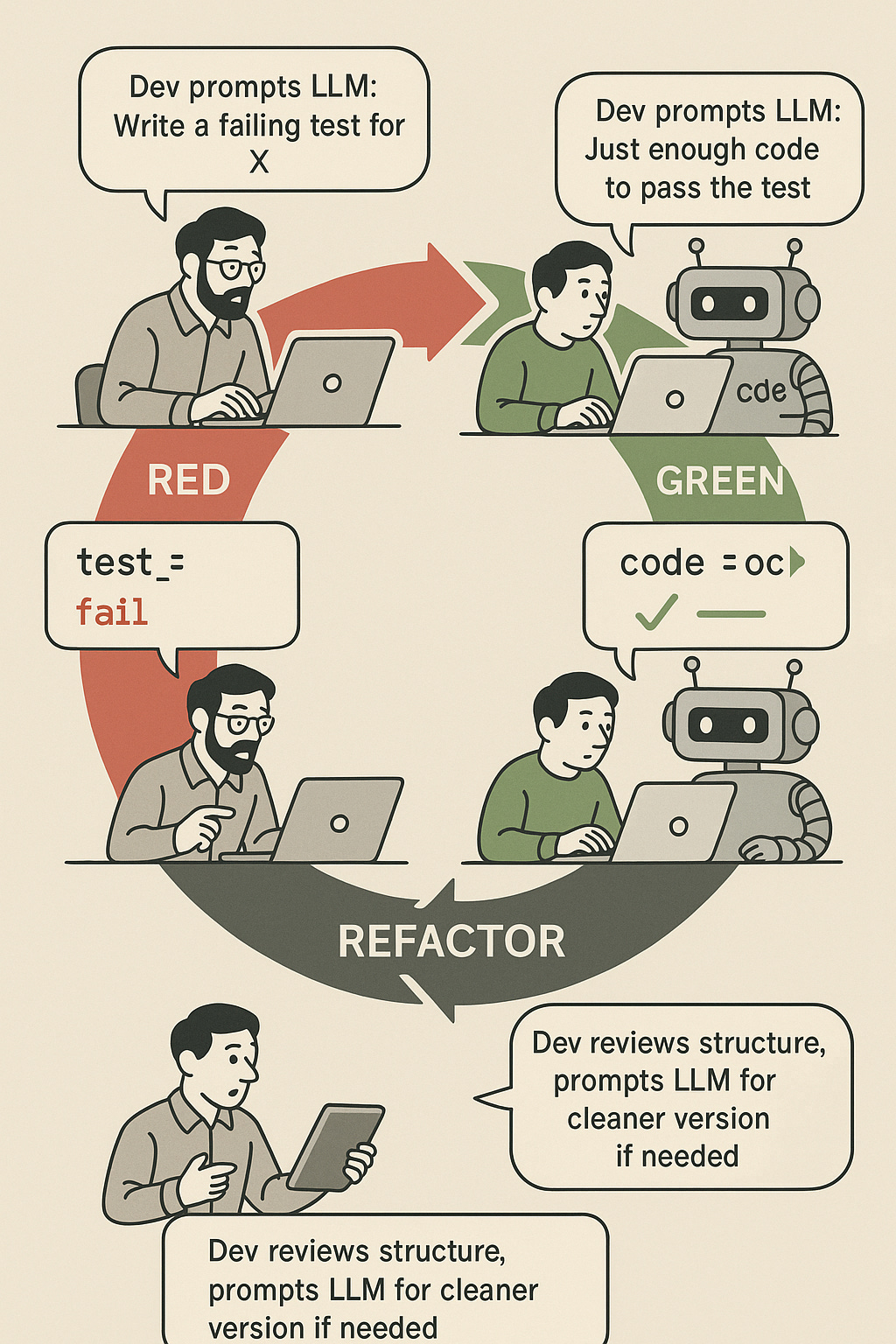
This is the human-led process, a tight cycle of Red-Green-Refactor, that ensures design integrity and deepens comprehension even when AI assists with code. This process is how you maintain control and build your own deep mental model of the codebase.
Red (Write a failing test): You write a small, executable test for something that doesn't exist yet. This isn't just about testing behaviour; it's about precisely defining a tiny piece of what you need. When we say "unit," we mean a testable behaviour or specific feature slice, not necessarily a single function or class. This lets the tests drive the design, even if that behaviour spans multiple functions or classes. It forces you, the human, to think about the desired outcome, the inputs, and the outputs, even before writing any production code. This step is a design exercise in miniature.
Green (Write just enough code to pass the test): You then write the minimal amount of production code needed to make that failing test pass. The goal here is strict functionality.
Refactor (Improve the code while keeping tests green): Once the test passes, you clean up the code – improving its design, readability, and structure – with full confidence that your tests are guarding against regressions. This is where design truly emerges and solidifies.
This Red-Green-Refactor cycle becomes the human-led process that ensures design integrity. It's the clear framework that guides LLMs' unpredictable nature, forcing you to stay in control of how the software's design evolves. Crucially, it helps you build your own deep mental model of the codebase, even if an AI is helping with the coding details. It's not about letting AI do the design; it's about making TDD the explicit architect of understanding.
Countering the "Dump": TDD's Incremental Guidance for LLMs
The core problem with LLM-dumped code, as we discussed, is its monolithic nature that skips human design. This is exactly where TDD steps in. TDD doesn't just check LLM output; it fundamentally changes how you interact with the AI to stop the "dump" from happening.
With TDD, you stay in control by being the architect of incremental design. Instead of giving the LLM a huge prompt for a whole feature, you break the problem down into its smallest, testable behaviours. Each Red step in the TDD cycle becomes a precise, human-defined instruction for the LLM. You write a small, failing test that defines only the next piece of desired behaviour.
This is where prompt engineering becomes super important. It's not about crafting one huge prompt for everything. It's about:
Prompting for Tests: You might ask the LLM to help draft the failing test itself from a clear requirement, but ultimately, you decide if that test really captures the small behaviour you want.
Prompting for Minimal Code: Once you have that small, failing test (the Red state), you then tell the LLM to generate only the bare minimum production code needed to make that specific test pass. This is key. We're explicitly telling the AI to not generate anything more than what's needed for this current, narrow step.

This iterative, test-driven prompting acts as a firm leash on the LLM's otherwise unpredictable and "dumping" tendencies. It forces the AI to generate code in small, easy-to-handle chunks, each directly tied to a human-understood and human-verified requirement. This approach has been empirically shown to significantly improve the correctness and efficiency of LLM-generated code in recent academic studies by Ahmed et al. (2024). This way, the design isn't some surprise in a massive dump; it emerges bit by bit under human guidance. This makes sure that even when LLMs write the code, you stay firmly in control of how the design evolves and why it's built that way.
Understanding Through Iteration: Building the Developer's Mental Model (Not Just Validating)
Beyond just stopping monolithic code dumps and guiding LLM output, TDD does something even bigger: it actively builds your real understanding of the codebase. This isn't about just checking something someone else made; it's about truly grasping the system as it grows.
When you, the human developer, go through the Red-Green-Refactor cycle, you're constantly solving problems and clarifying design. Each "Red" step forces you to precisely define a desired behaviour, its inputs, and what you expect back. Writing a failing test before any production code exists makes you think deeply about the problem, how different parts of the system connect, and the detailed logic needed. This hands-on involvement is totally different from just reviewing a big chunk of pre-generated code. Even if an LLM helps with the "Green" implementation, your mental picture of why that test was written, what behaviour it represents, and how it fits into the bigger design is already forming.

This iterative process – defining small behaviours, checking their implementation, and then putting them together – steadily builds a detailed, solid understanding of the code's architecture and logic in your mind. You own the design, not just by saying "yes" to it, but by actively creating it through tests. This level of understanding is super important for:
Effective Debugging: When something breaks, you have a mental map of the system's design and what it's supposed to do. This lets you figure out problems faster, instead of just fumbling through opaque, AI-generated code.
Confident Refactoring: Knowing why each part of the code exists and what it supports (because your tests guard it) empowers you to clean up and optimise without fear, even if an LLM wrote some of it initially.
Strategic Evolution: With a deep understanding of the system's design, you can make smart choices about future features, scaling, and architectural changes, avoiding the traps of blindly adding to a system you don't really know.
Basically, TDD changes you from someone who just gets AI-generated code into an active, understanding architect. It makes sure that even when LLMs handle the coding details, your comprehension of the design stays central and gets stronger all the time.
TDD as the Safety Net for AI-Assisted Refactoring and Evolution
One of the unsung heroes of a good TDD practice, especially now with AI, is its role as an amazing safety net for refactoring and continuous code evolution. As we have talked about, LLM-generated code, without TDD's guidance, can end up being opaque. Developers then hesitate to change it, worried they'll break hidden parts or mess things up. TDD fixes this fear directly.
When you have a full set of human-guided, behaviour-driven tests (built step-by-step through Red-Green-Refactor), those tests become your ultimate guardian. They're like executable rule books that constantly check if the system is behaving as expected. This means you can confidently refactor the underlying code, even if parts of it were initially generated by an LLM, knowing your tests will immediately tell you if you accidentally broke anything important.
This combination is powerful. While LLMs can sometimes suggest refactoring, it's your understanding of the design (built through TDD) combined with the safety net of your tests that lets you refactor with real confidence. You can use the LLM for ideas on optimising or changing structures, but the TDD test suite is the ultimate truth-teller. It ensures the code's core behaviour stays intact. This lets developers actively make their codebases better, instead of being paralysed by how complex or opaque un-understood, LLM-dumped code might seem. It turns the codebase from a fragile problem into a flexible asset, ready for constant improvement and adaptation.
Final Thoughts
The ultimate goal of using AI in software development is higher quality, not just faster delivery. TDD is the discipline that transforms LLMs into a collaborative force ensuring quality.